Sequence-to-Sequence (Seq2Seq) Data
Seq2Seq refers to a scenario where both the input and the output of a model are ordered sequences. We aren't just predicting a single number (like "Will the price go up?"), but rather mapping one series of events to another.
Standard neural networks (like a simple Feed-Forward network) require a fixed number of input features and produce a fixed number of outputs. However, financial data is fluid, You might have 20 days of
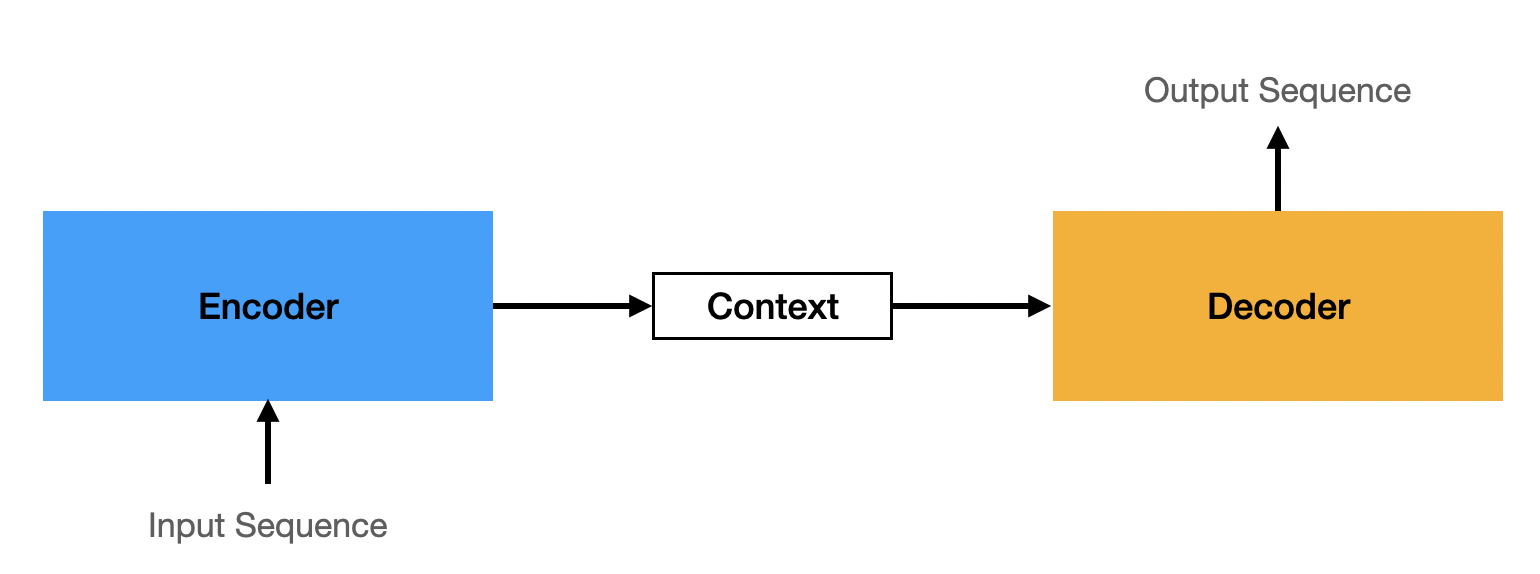
The Encoder-Decoder architecture acts as a "bridge" that compresses any number of inputs into a single mathematical representation and then expands it into the desired number of outputs.
What is an Encoder-Decoder?
Think of it as a two-part translation system:
- The Encoder (The Summarizer): The Encoder reads the input sequence one step at a time. Its job is to create a Context Vector (
). - The Decoder (The Generator): The Decoder takes that Context Vector and "unpacks" it to generate the output sequence.
The Context Vector (
To illustrate how the Encoder-Decoder and Transformer architectures work, let's use a specific financial forecasting task:
Predicting the next 3 days of a stock's closing price based on the previous 5 days of trading data.
- Input (
): 5 days of (Price, Volume) pairs. - Output (
): 3 days of predicted Prices.
Imagine you are a senior trader. You have an analyst (the Encoder) who watches the market for 5 days. You don't want to see every single tick or trade; you want a summary that tells you everything you need to know to make a 3-day forecast.
The Financial Input (
Let's say our 5-day window looks like this:
-
Day 1: Price +1%, High Volume (News breakout)
-
Day 2: Price +0.2%, Low Volume (Consolidation)
-
Day 3: Price -0.1%, Low Volume (Quiet)
-
Day 4: Price +0.5%, Moderate Volume (Trend resumes)
-
Day 5: Price +1.2%, High Volume (Bullish close)
The Encoding Process
The Encoder processes these one by one. By Day 5, it doesn't just "remember" Day 5; it has updated its internal hidden state
While the raw data is a sequence of prices and volumes,
Mathematically, these numbers don't represent "Price" or "Volume" directly. Instead, they represent High-Level Features (or latent variables) that the model has learned are important for forecasting.
To visualize it, imagine
Each "slot" in that 128-number vector might correspond to a specific market concept the neural network has discovered, such as:
- Slot 1: Strength of the upward trend.
- Slot 2: Current market volatility relative to the 5-day average.
- Slot 3: Whether the volume spike on Day 5 was "unusual."
| Stage | Data Shape | Representation |
|---|---|---|
| Input ( |
5 days, each with (Price, Volume) | |
| Processing | The hidden state at each of the 5 steps | |
| Context ( |
The final state |
The number 128 isn't a fixed mathematical constant; it is a hyperparameter chosen by the person designing the model.