Self-attention
Self-attention is an attention mechanism in which each token in a sequence computes its representation by attending to all tokens in the same sequence, including itself. It enables the model to capture contextual relationships and dependencies regardless of their distance in the sequence. Mathematically, for an input sequence transformed into Query (Q), Key (K), and Value (V) matrices, self-attention is computed as:
where the similarity between queries and keys determines the attention weights, and these weights are used to compute a weighted sum of the value vectors. This allows each token to dynamically focus on the most relevant parts of the sequence to build richer contextualized representations.
How Attention Mechanism Works
You are given a sequence:
Past data → x₁, x₂, x₃, x₄, x₅, ..., xₜ
Goal → predict something at time t
Traditional thinking
Treat all past equally:
- moving average
- or sequential memory (RNN/LSTM)
But reality says:
Not all past is equally useful.
Human intuition
Imagine you’re analyzing markets today.
You don’t think:
“Let me average last 100 days”
Instead you think
“When did market behave like this before?”
| Day | Market Condition | Should it matter? |
|---|---|---|
| 1 | calm uptrend | ❌ low importance |
| 2 | calm uptrend | ❌ |
| 3 | slight drop | ⚠️ medium |
| 4 | recovery | ⚠️ |
| 5 | volatility | ✅ high |
| 6 | crash | 🔥 very high |
Your brain assigns weights
Day1 → 0.05
Day2 → 0.05
Day3 → 0.15
Day4 → 0.15
Day5 → 0.25
Day6 → 0.35
You are doing:
- Compare present with past
- Measure similarity
- Assign importance
- Combine information
Attention is:
- NOT memory
- NOT averaging
It is:
is a mechanism that learns where to look in the input by adaptive pattern matching over history
How Attention Decides What to Focus On
We now formalize attention as a mathematical operator.
1. Problem Setup
We are given a sequence:
Goal: for each time step
So we aim for:
where:
= importance of time for time
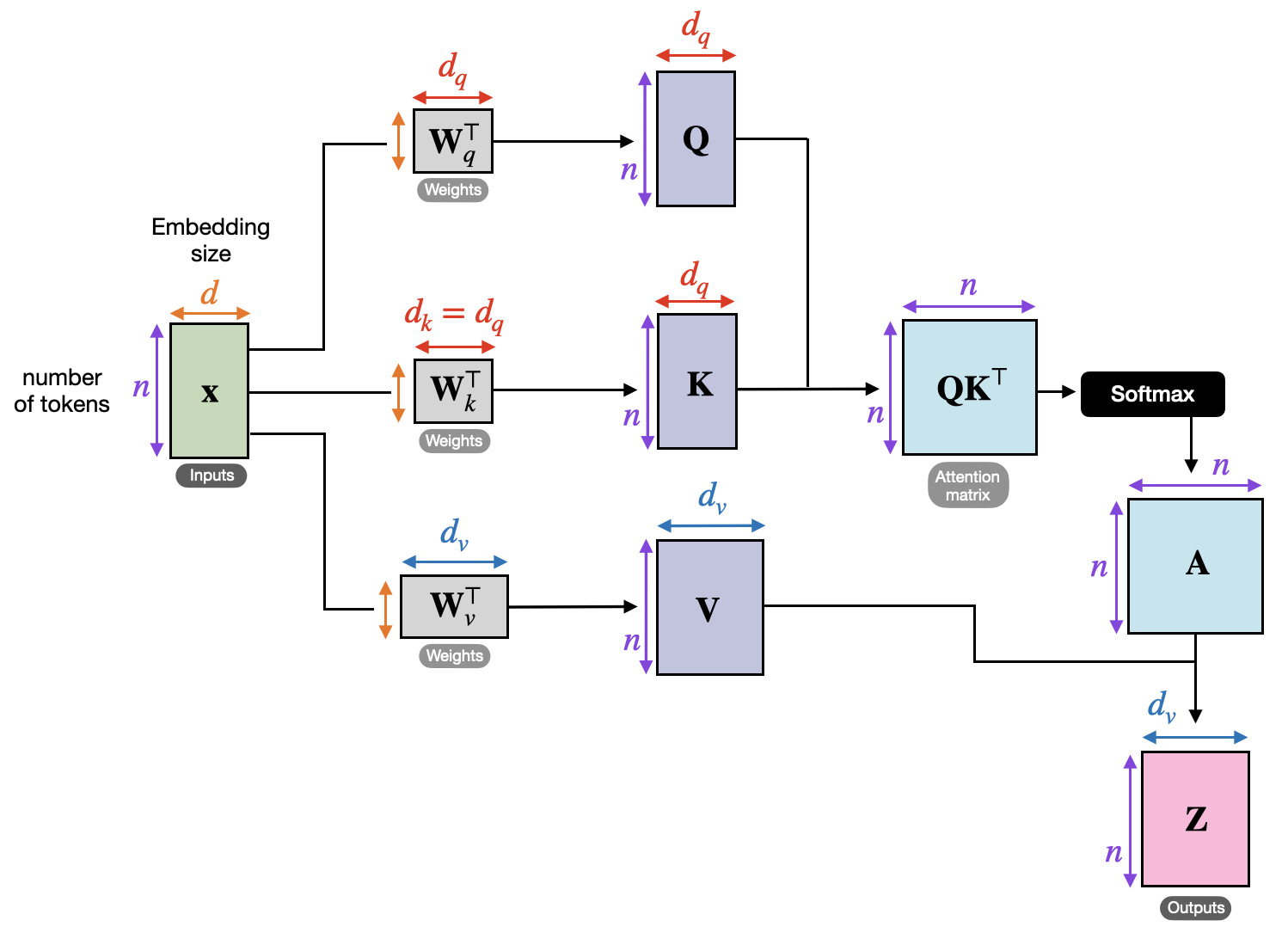
2. Learnable Projections
Instead of comparing raw inputs, we project them into three spaces:
where:
Here:
- Query
: what the current timestep is looking for - Key
: representation of past timestep for comparison - Value
: information stored at timestep
3. Similarity Function
We compute similarity between time
- Large value → aligned → similar
- Small value → unrelated
4. Scaling
We scale the dot product:
Without scaling:
- variance of dot product grows with dimension
- softmax becomes extremely sharp
5. Softmax Normalization
Convert scores into probabilities:
So for each
6. Output Computation
Final representation:
Matrix Form :
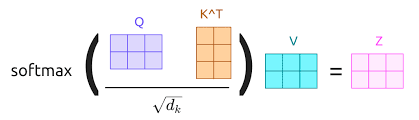
At time
means:
construct today’s signal as a weighted combination of past regimes, where weights depend on similarity to current conditions
import numpy as np
def softmax(x):
# subtract max for numerical stability
x = x - np.max(x, axis=-1, keepdims=True)
exp_x = np.exp(x)
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def attention(X, W_Q, W_K, W_V):
"""
X: (T, d)
W_Q, W_K, W_V: (d, d_attn)
"""
# Step 1: Linear projections
Q = X @ W_Q # (T, d_attn)
K = X @ W_K # (T, d_attn)
V = X @ W_V # (T, d_attn)
# Step 2: Similarity
S = Q @ K.T # (T, T)
# Step 3: Scaling
d_attn = Q.shape[1]
S = S / np.sqrt(d_attn)
# Step 4: Softmax
A = softmax(S) # (T, T)
# Step 5: Output
H = A @ V # (T, d_attn)
return H, A
Case Studies
We are given a time series with 3 timesteps:
We define projection matrices:
Attention Dimension:
Compute the final attention output matrix
Step 1: Compute Q, K, V
Step 2: Compute Similarity Matrix
Transpose K
Similarity Matrix,
Step 3: Scaling
Step 4: Softmax
Softmax formula applied to each element:
Row 1
Row 2
Row 3
Final Attention Matrix:
Step 5: Compute Output
Row 1
Row 2
Row 3
Final Output
Market reacts to War News
We have 5 timesteps with price + news features:
Feature meaning
- First value = return
- Second value = news signal (1 = war, 0 = none)
Value transformation
So:
Compute:
At time 5, model compares:
Similarity reasoning
: no news → low similarity : war + crash → HIGH similarity : no news → moderate : identical → highest
Approx attention weights
Compute values
Output:
Intuition
- Model ignores calm periods
- Focuses on past war events
- Builds a “war-aware market state”
Key takeaway
Pytorch Implementation
import torch
import torch.nn.functional as F
def attention_torch(X, W_Q, W_K, W_V):
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
d_attn = Q.size(-1)
S = Q @ K.transpose(-2, -1)
S = S / torch.sqrt(torch.tensor(d_attn, dtype=torch.float32))
A = F.softmax(S, dim=-1)
H = A @ V
return H, A